欢迎各位加入免费知识星球,获取PDF论文,欢迎转发朋友圈分享快乐。
论文阅读模块将分享点云处理,SLAM,三维视觉,高精地图相关的文章。公众号致力于理解三维视觉领域相关内容的干货分享,欢迎各位加入我,我们一起每天一篇文章阅读,开启分享之旅,有兴趣的可联系微信dianyunpcl@163.com。
摘要
尽管运动恢复结构(SfM)作为一种成熟的技术已经在许多应用中得到了广泛的应用,但现有的SfM算法在某些情况下仍然不够鲁棒。例如,比如图像通常在近距离拍摄以获得详细的纹理才能更好的重建场景细节,这将导致图像之间的重叠较少,从而降低估计运动的精度。在本文中,我们提出了一种激光雷达增强的SfM流程,这种联合处理来自激光雷达和立体相机的数据,以估计传感器的运动。结果表明,在大尺度环境下,加入激光雷达有助于有效地剔除虚假匹配图像,并显著提高模型的一致性。在不同的环境下进行了实验,测试了该算法的性能,并与最新的SfM算法进行了比较。

CMU Smith Hall重建点云模型(灰色),覆盖视觉特征点(红色)
相关工作与主要贡献
基于机器人的检测需求越来越大,需要对桥梁、建筑物等大型土木工程设施的高分辨率图像数据进行处理。这些应用通常使用高分辨率、宽视场(FOV)相机,相机在离结构表面近距离处拍摄,以获得更丰富的视觉细节。这些特性对标准SfM算法提出了新的挑战。首先,大多数可用的全局或增量SfM方案都是基于单个摄像机的,因此不能直接恢复比例。更重要的是,由于视场的限制,相邻图像之间的重叠区域被缩小,从而导致姿态图只能局部连通,从而影响运动估计的精度。这个问题在大规模环境中变得更加重要。
为了解决上述挑战本文提出了一种新的方案,它扩展了传统的SfM算法,使之适用于立体相机和LiDAR传感器。这项工作基于一个简单的想法,即激光雷达的远距离能力可以用来抑制图像之间的相对运动。更具体地说,我们首先实现了一个立体视觉SfM方案,它计算摄像机的运动并估计视觉特征(结构)的三维位置。然后将激光雷达点云和视觉特征融合到一个单一的优化函数中,迭代求解该优化函数以最优化相机的运动和结构。在我们的方案中,LiDAR数据从两个方面增强了SfM算法:
1)LiDAR点云用于检测和排除无效的图像匹配,使基于立体相机的SfM方案对视觉模糊具有更强的鲁棒性;
2)LiDAR点云与视觉特征在联合优化框架中相结合,以减少运动漂移。我们的方案可以实现比最先进的SfM算法更一致和更精确的运动估计。
本文的工作主要有以下几个方面:
1)将全局SfM技术应用于立体摄像系统,实现了摄像机在真实尺度下的运动初始化。
2) 激光雷达数据被用来排除无效的图像匹配,进一步加强了方案的可靠性。
3) 通过联合立体相机和激光雷达的共同的数据,扩展了我们先前提出的联合优化方案,提高了所建模型的精度和一致性。
激光雷达增强的双目SFM
该方案以一组立体图像和相关的LiDAR点云作为输入,以三角化特征点和合并的LiDAR点云的格式生成覆盖环境的三维模型。下图显示了我们的LiDAR增强SfM方案的过程
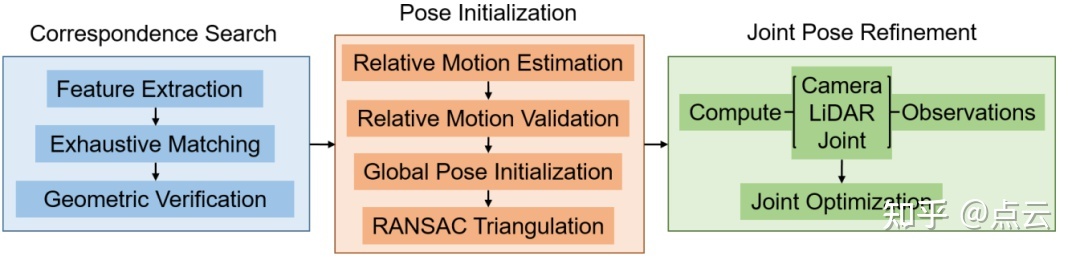
光雷达增强的双目SFM方案
A、 对应特征点搜索
给定立体图像对,计算对应关系包括特征提取、匹配和几何验证。首先,我们依赖OpenMVG库从图像中提取SIFT特征。然后使用所提供的级联哈希方法对特征进行穷尽匹配。最后,通过对双目极线约束进行几何的验证,验证了两幅图像之间的匹配。具体地说,利用RANSAC估计基本矩阵F,然后用来检查匹配特征的极线误差。只保留几何上一致的特征,以便进一步计算。
B、 相对运动估计
由于立体图像对是预先校准的,所以我们将一对左右图像作为一个独立的单元,为了估计相对运动,标准的立体匹配方法依赖于两对图像中所有四幅图像所观察到的特征点,而我们观察到许多点只被三幅甚至两幅图像共享。忽略这些点可能会丢失估计相机运动的重要信息,特别是在图像重叠有限的情况下。因此,这里选择显式地处理两个位姿点之间共享视图的不同情况。具体来说,我们考虑至少3个视图共享的特征点,以确保尺度的重建。虽然只有2个视图的点可以帮助估计旋转和平移方向,但是由于这些点通常来自于下图所示的小重叠区域,所以这里忽略它们。另一方面,两个位姿点之间也可能存在多种类型的共享特性。为了简化问题,我们选择对应关系最多的类型来求解相对运动。在三视图情况下,首先用立体图像对,对特征点点进行三角化,然后用RANSAC+P3P算法求解。在四视图的情况下,我们遵循标准的处理方法,首先对两个站点中的点进行三角化,然后应用RANSAC+PCA配准算法找到相对运动。在这两种情况下,都使用非线性优化程序来优化计算的姿态和三角化,通过最小化内线的重投影误差。最后,对所有姿态进行变换以表示左摄像机之间的相对运动。

两视图要素的区域示例。左:一位姿右图像;中右:另一位姿的左右图像。共同的小区域靠近边界并用红框标记。
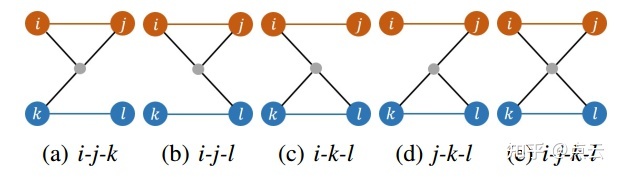
两个位姿点(红色和蓝色圆圈对)之间共享特征(灰点)的示例。彩色条表示已知的校准后的立体图像对。(a)-(d)三视图;(e)四视图。
C、 相对运动验证
一旦找到了相对运动,就可以建立一个姿态图,其中节点表示图像帧的姿态,边表示相对运动。全局姿态可以通过平均位姿图上的相对运动来求解。然而,由于环境中的视觉模糊性(见下图),可能存在无效的边缘,并且直接平均相对运动可能会产生不正确的全局姿势。因此,设计了一个两步边缘验证方案来去除异常值。
(1)在第一步中,检查所有图像帧对的激光雷达点云的重叠,并剔除不一致的点云。
(2)第二步中检查回环的一致性。(具体方法可在论文中有详细说明)
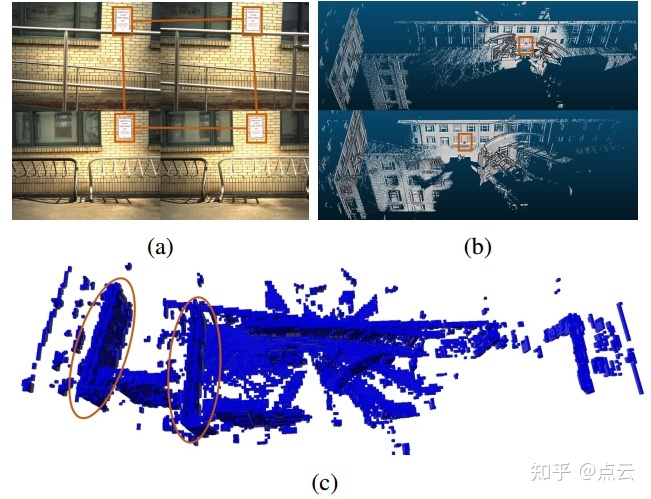
由于视觉模糊导致的无效相对运动的例子。(a) 由于相同的停车标志,两对图像匹配不正确。(b) 相应的点云来自两个车站,标志用红框标出。(c) 合并的占用网格显示不正确的对齐方式(红色椭圆)。在这种情况下,一致性比为0.56,而有效相对运动的一致性比通常超过0.7
D、 全局位姿初始化
这部分主要介绍优化全局帧的代价函数:
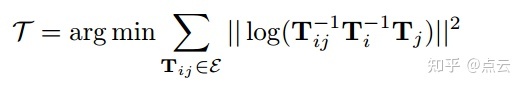
E、三角化与RANSAC
本文采用文鲁棒三角化方法,对每个三维特征点使用RANSAC来寻找最佳的三角化视图。对于每个轨迹,它是不同相机视图中一个特征点的观察值的集合,随机对两个视图进行采样,并使用DLT方法对该点进行三角化。通过将该点投影到其他视图上并选择具有较小重投影误差的视图,可以找到更匹配的视图。此过程重复多次,并保留最大的一组内部视图(至少需要3个视图)。最后,通过最小化重投影误差,利用内联视图优化特征点在全局结构中的位姿。
F、联合位姿优化
基于视觉的SfM算法的位姿优化通常通过束调整(BA)来实现。然而,由于多个系统原因,如特征位置不准确、标定不准确、对应异常值等,位姿估计在长距离内可能会产生较大的漂移,尤其是在无法有效地发现闭合环路的情况下。为了解决这个问题,我们考虑利用激光雷达的远距离能力来限制相机的运动,该方案将相机机和激光雷达观测值联合最优化。这部分内容可查看原文理解公式。
实验结果
A、实验装置
下图具有多个机载传感器,包括两个Ximea彩色摄像头(1200万像素,全局快门)和一个安装在连续旋转电机上的Velodyne Puck激光雷达(VLP-16)。利用编码器测量的电机角度,将VLP-16的扫描点转换成固定的基架。

传感器盒子和数据集。
B、 相对运动估计
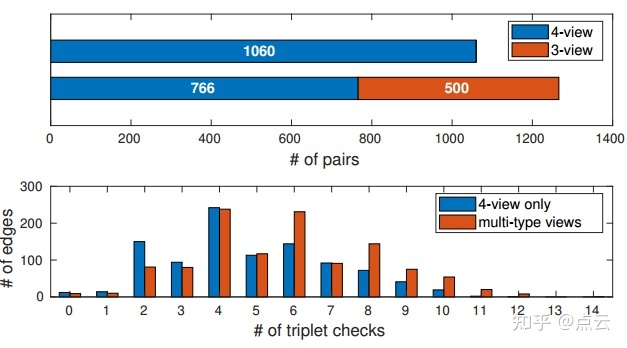
上图:从4个视图和3个视图点显示求解的对数。下图:不同三元组检查的边数直方图。
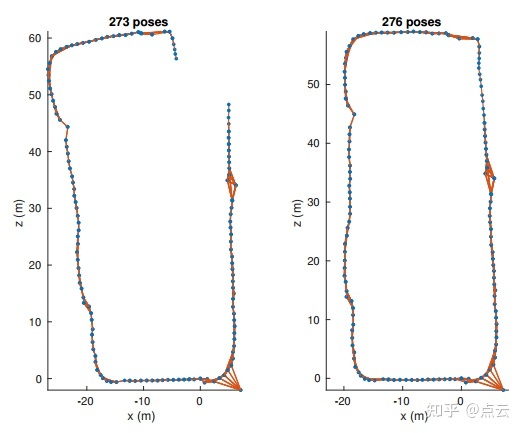
左图:初始化的位姿图有4个视图特征。右:使用多视图初始化位姿图
C、 相对运动验证
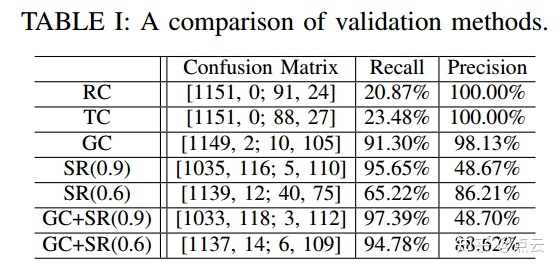
这里比较了所提出的基于网格的检查(GC,阈值为0.6)和成功率检查(SR)与OpenMVG使用的旋转循环检查和transform(旋转和平移)循环检查(TC)的异常值排除法的性能。
D、 联合测量
这里展示联合观测建模在联合优化中的优势。如下图所示
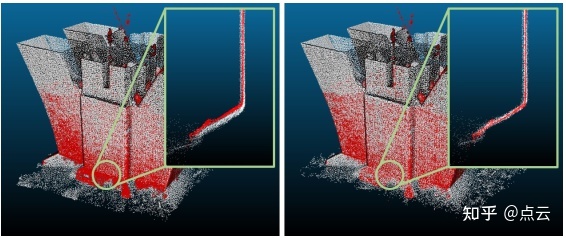
激光雷达点云(灰色)与重建视觉特征(红色)叠加。左:没有联合观测。右:联合观测。
E、重建
对收集到的数据集的重建结果下图所示。在第一行,展示了小型混凝土结构的重建。第二行比较了使用COLMAP、OpenMVG和我们的方案Smith-Hall重建结果。在这三个测试中,使用左右图像进行重建。然而,COLMAP和OpenMVG都无法处理由停车标志,和有限的重叠图像造成的视觉模糊。因此,生成的模型要么不一致,要么不完整。使用我们的方案有助于有效地排除无效的运动,并允许建立一个更一致的模型。

重建的结果对比
总结
本文提出了一种利用激光雷达信息提高立体SfM方案的鲁棒性、准确性、一致性和完备性的LiDAR增强立体SfM方案。实验结果表明,该方法能有效地找到有效的运动位姿,消除视觉模糊。此外,实验结果还表明,结合相机和激光雷达的联合观测有助于完全约束外部变换。最后,与最先进的SfM方法相比,LiDAR增强SfM方案可以产生更一致的重建结果。
